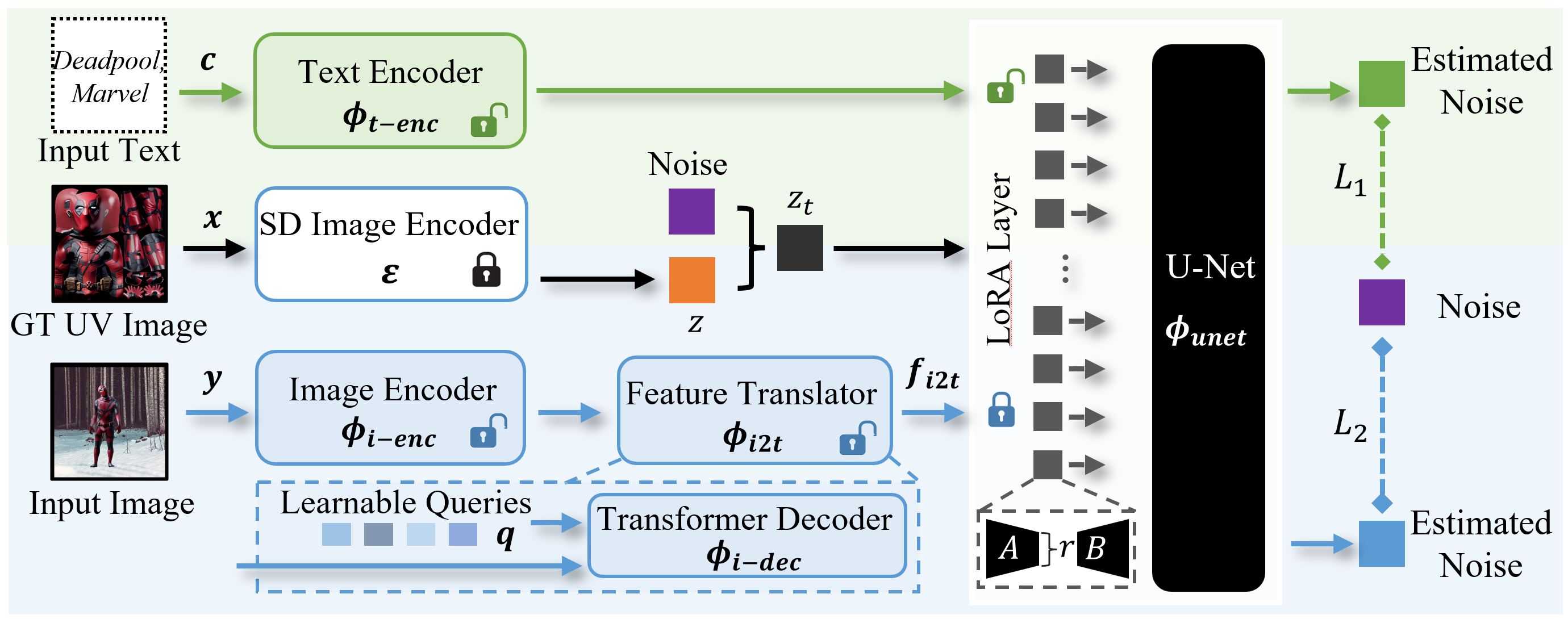
TexDreamer
TexDreamer is the first zero-shot high-fidelity 3D human texture generation model that supports both text and image inputs.
Jewish girl, purple button-up shirt, black high-waisted pants, brown hair
Darth Vader
Joe Biden
Ant-man
Norwegian girl, green lace top, wide-leg pants, brown hair
Irish woman, white wrap blouse, high-waisted denim pants, curly hair, teenager
Korean woman, black shirt, blue jeans, black hair, young
Commodus
Indian girl, pink sweater, dark wash jeans, black hair
Bill Gates, blue shirt, glasses
Pennywise from movie IT
Tom Hardy, black tuxedo, buzz cut
Isaac Newton, black suit, medium-length white hair
Michael Jackson, red jacket, black curly hair
Dark Souls, The Chosen Undead
Steve Jobs, black turtleneck
TexDreamer
TexDreamer is the first zero-shot high-fidelity 3D human texture generation model that supports both text and image inputs.
Jewish girl, purple button-up shirt, black high-waisted pants, brown hair
Darth Vader
Joe Biden
Ant-man
Norwegian girl, green lace top, wide-leg pants, brown hair
Irish woman, white wrap blouse, high-waisted denim pants, curly hair, teenager
Korean woman, black shirt, blue jeans, black hair, young
Commodus
Indian girl, pink sweater, dark wash jeans, black hair
Bill Gates, blue shirt, glasses
Pennywise from movie IT
Tom Hardy, black tuxedo, buzz cut
Isaac Newton, black suit, medium-length white hair
Michael Jackson, red jacket, black curly hair
Dark Souls, The Chosen Undead
Steve Jobs, black turtleneck